
A new publication in Opto-Electronic Advances discusses efficient stochastic parallel gradient descent training for on-chip optical processors.
With the explosive growth of the global data volume, space-division multiplexing (SDM) technology has emerged as a promising solution to enhance communication capacity. Over the past few decades, SDM has been realized in few-mode fibers, multi-core fiber and free-space optical communication systems. However, all of these solutions face challenges of signal crosstalk because of the mixing between different channels during the transmission of optical signals, resulting in a degradation in signal quality at the receiver.
Therefore, digital signal processing (DSP) is necessary for descrambling. Unfortunately, high-speed DSP chips in the electrical domain are highly complicated, difficult to design, and have high power consumption. In recent years, integrated reconfigurable optical processors have been exploited to undo channel mixing in the optical domain. However, the gradient descent algorithms must update variables one by one to calculate loss function with each iteration, which leads to a large amount of computation and a long training time.
In addition, swarm intelligence algorithms such as the genetic algorithm (GA) and the particle swarm optimization (PSO) algorithm have a large enough population size to ensure the reliability of training results, which also require a large amount of computation. Therefore, it is important to find an efficient optimization algorithm suitable for optical matrix configuration for online training of large-scale photonic computing chips and multi-dimensional optical communication systems.
Progress in the online training of optical matrix computing chips has been made; compared to the discrete gradient descent algorithm, GA and PSO algorithm, this method greatly reduces the number of operations, which can greatly save power consumption within the training process, and is expected to be applied to the online training of ultra-large-scale optical matrix computing chips.
In order to verify the feasibility of the proposed optimization method, the study authors designed and fabricated a 6×6 reconfigurable optical processor chip based on cascaded Mach-Zehnder Interferometers (MZIs) and carried out online training experiments including the optical switching matrix and optical signal descrambling matrix.
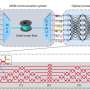
The paper shows the application scenario of an optical processor in the MDM optical communication system and the internal structure of the processor. It also shows the training results, and it can be seen that the training effect is relatively good for the optical switching and optical signal descrambling tasks in the multi-dimensional optical communication system.
On this basis, this reconfigurable optical processor chip for high-speed optical communication systems was used to compensate for crosstalk caused by mode mixing during transmission. The experimental setup and obtained results are explained within the study. It can be seen that the quality of the signal is significantly improved when the light passes through the trained photonic chip and the bit error rate (BER) is greatly reduced.
Finally, the computational effort of the SPGD algorithm is compared with the traditional gradient algorithm, GA and PSO algorithm when the optical matrix scale is expanded to 10×10, 16×16, and 32×32. The results show that the increase in the computational cost of SPGD algorithm is less than that of other algorithms.
More information: Yuanjian Wan et al, Efficient stochastic parallel gradient descent training for on-chip optical processor, Opto-Electronic Advances (2024). DOI: 10.29026/oea.2024.230182
Provided by Compuscript Ltd
Citation: Team develops efficient stochastic parallel gradient descent training for on-chip optical processors (2024, May 1) retrieved 1 May 2024 from https://techxplore.com/news/2024-05-team-efficient-stochastic-parallel-gradient.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no part may be reproduced without the written permission. The content is provided for information purposes only.